有没有相关的论文或文献参考?
这个数据集是基于什么背景创建的?
数据集的作者是谁?
能帮我联系到这个数据集的作者吗?
这个数据集如何下载?
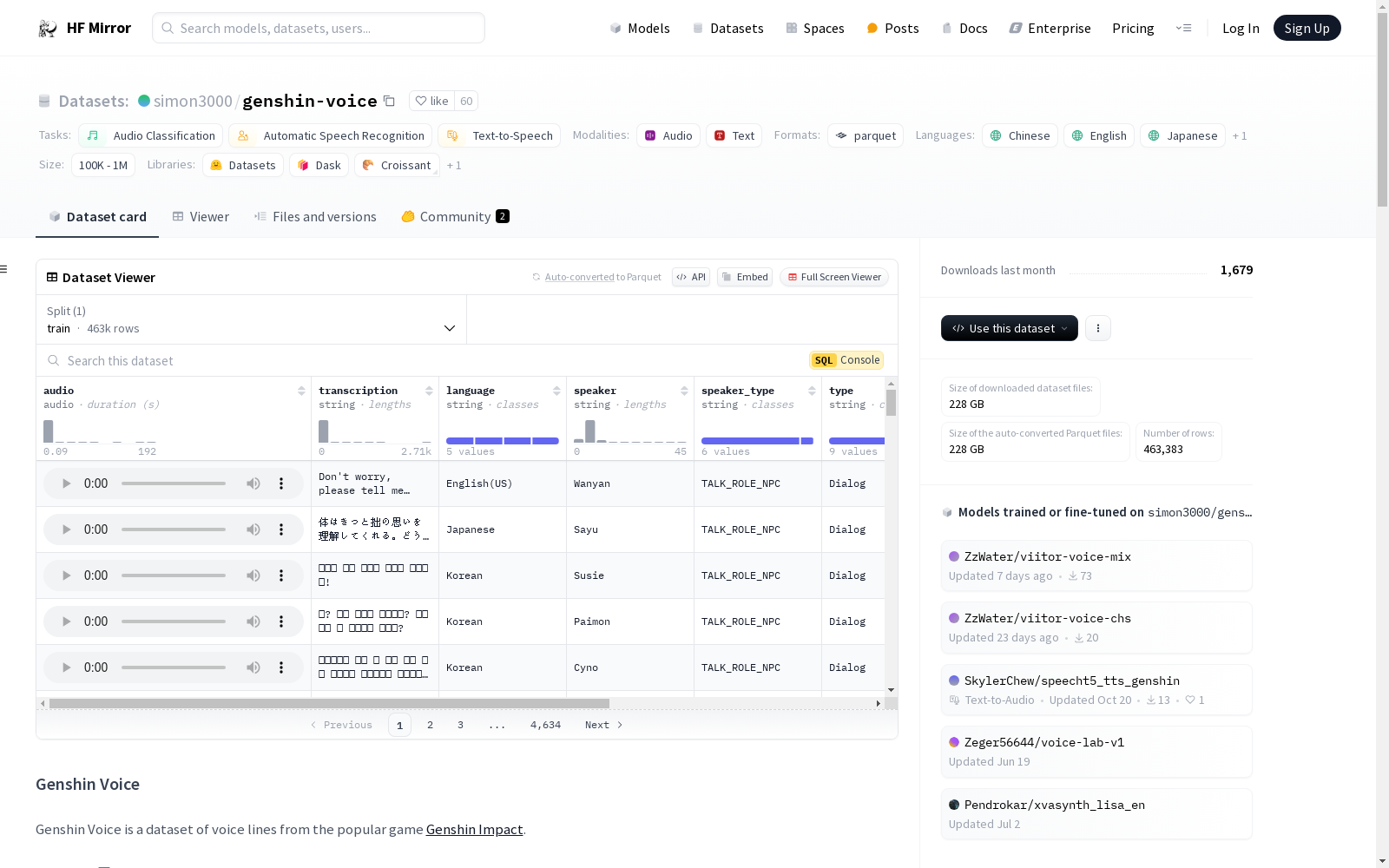
数据集名称: Genshin Voice
数据集描述: Genshin Voice 是一个包含流行游戏《Genshin Impact》中角色语音线的数据集。该数据集涵盖多种语言,包括中文、英文、日文和韩文,内容涉及问候、战斗和故事对话等多个主题。
数据集特征:
数据集拆分:
数据集大小与下载大小:
数据集配置:
数据集使用示例: python from datasets import load_dataset import soundfile as sf import os
dataset = load_dataset(simon3000/genshin-voice, split=train, streaming=True) chinese_ganyu = dataset.filter(lambda voice: voice[language] == Chinese and voice[speaker] == Ganyu and voice[transcription] != )
数据集创建:
数据集注释:
数据集偏差、风险和限制:
许可证信息:
其他信息:
rock-crack and concrete-crack dataset, CT-slice-crack dataset
岩石裂缝与CT岩心裂缝语义分割数据集,用于识别道路、建筑物和其他民用结构上的裂缝。
github 收录
PU Dataset
德国帕德博恩大学(PU)轴承故障诊断数据集提供了丰富的轴承故障信号数据,包括内圈、外圈和滚动体故障等多种类型的轴承故障。与其他数据集相比,PU数据集的特色在于包含了大量的电机驱动系统故障数据,为轴承故障诊断研究提供了一个全面的实验平台。
github 收录
MeSH
MeSH(医学主题词表)是一个用于索引和检索生物医学文献的标准化词汇表。它包含了大量的医学术语和概念,用于描述医学文献中的主题和内容。MeSH数据集包括主题词、副主题词、树状结构、历史记录等信息,广泛应用于医学文献的分类和检索。
www.nlm.nih.gov 收录
CACD
跨年龄名人数据集是用于跨年龄人脸识别和检索的数据集。它包含 2,000 位名人的 163,446 张图像。该数据集于 2014 年由马里兰大学计算机科学系发表,论文名为 cross-age Reference Coding for Age-invariant Face Recognition and Retrieval。
OpenDataLab 收录
轴承故障数据集
本项目集成了多个公开的轴承故障数据集,所有数据均被处理为1秒/个的数据样本,并使用fft得到其频域特征。支持通过数据集、通道、故障、严重程度对所有样本进行筛选,并选择时域或频域显示。
github 收录