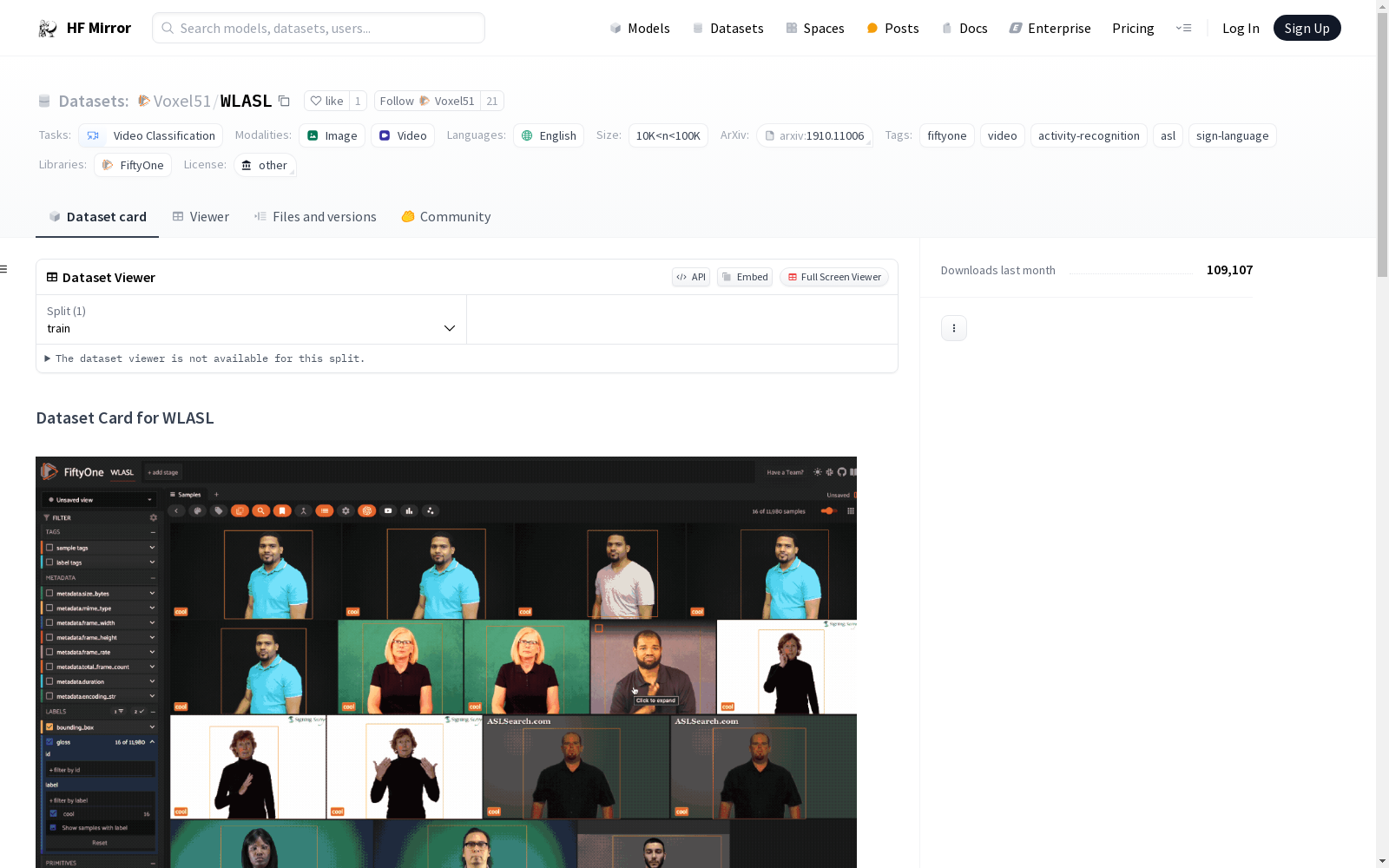
Voxel51/WLASL|手语识别数据集|视频分类数据集
收藏数据集概述
基本信息
- 数据集名称: WLASL
- 数据集大小: 10K<n<100K
- 任务类别: video-classification
- 语言: en
- 许可证: other
- 标签: fiftyone, video, activity-recognition, asl, sign-language
- 样本数量: 11980
数据集描述
WLASL是一个专为Word-Level American Sign Language (ASL)识别设计的大型视频数据集,包含2000个ASL中的常用词汇。该数据集旨在促进手语理解的研究,并最终改善聋人和听觉社区之间的交流。
数据集来源
- 仓库: https://github.com/dxli94/WLASL
- 论文: https://arxiv.org/abs/1910.11006
- 主页: https://dxli94.github.io/WLASL/
- 演示: https://try.fiftyone.ai/datasets/asl-dataset/samples
使用许可
WLASL数据仅限于学术和计算用途,不允许商业使用。数据集受Computational Use of Data Agreement (C-UDA)许可。
引用信息
bibtex @misc{li2020wordlevel, title={Word-level Deep Sign Language Recognition from Video: A New Large-scale Dataset and Methods Comparison}, author={Dongxu Li and Cristian Rodriguez Opazo and Xin Yu and Hongdong Li}, year={2020}, eprint={1910.11006}, archivePrefix={arXiv}, primaryClass={cs.CV} }
@inproceedings{li2020transferring, title={Transferring cross-domain knowledge for video sign language recognition}, author={Li, Dongxu and Yu, Xin and Xu, Chenchen and Petersson, Lars and Li, Hongdong}, booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition}, pages={6205--6214}, year={2020} }