有没有相关的论文或文献参考?
这个数据集是基于什么背景创建的?
数据集的作者是谁?
能帮我联系到这个数据集的作者吗?
这个数据集如何下载?
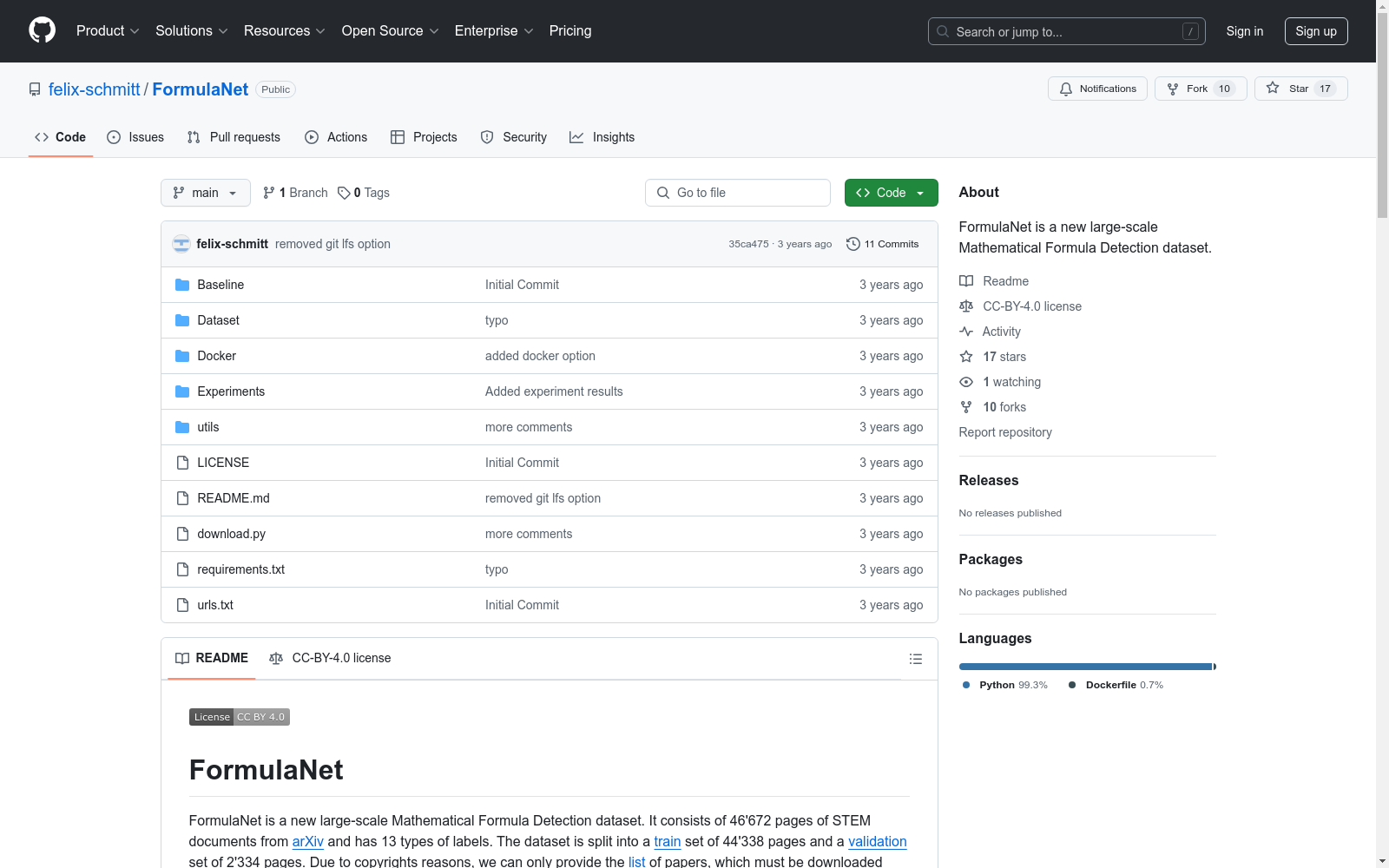
D4LA-版面分析数据集
# D4LA 文档版面分析数据集 (the most Diverse and Detailed Dataset ever for Document Layout Analysis) ## 数据集概述 D4LA是面向文档版面分析的数据集。 ### 数据集简介 包含12类文档工27类文档版面类型,详细如下:  ### 标注格式 ``` D4LA ├── train_images │ ├── 1.jpg ├── test_images │ ├── 2.jpg ├── VGT_D4LA_grid_pkl │ ├── 1.pkl │ └── 2.pkl ├── json │ ├── train.json │ └── test.json ``` ### 引用方式 If you find this repository useful, please consider citing our work: ``` @inproceedings{da2023vgt, title={Vision Grid Transformer for Document Layout Analysis}, author={Cheng Da and Chuwei Luo and Qi Zheng and Cong Yao}, year={2023}, booktitle = {ICCV}, } ``` ### Clone with HTTP ```bash git clone https://www.modelscope.cn/datasets/damo/D4LA.git ```
魔搭社区 收录
China Groundgroundwater Monitoring Network
该数据集包含中国地下水监测网络的数据,涵盖了全国范围内的地下水位、水质和相关环境参数的监测信息。数据包括但不限于监测站点位置、监测时间、水位深度、水质指标(如pH值、溶解氧、总硬度等)以及环境因素(如气温、降水量等)。
www.ngac.org.cn 收录
Plant-Diseases
Dataset for Plant Diseases containg variours Plant Disease
kaggle 收录
YOLO-dataset
该数据集用于训练YOLO模型,包括分类、检测和姿态识别模型。目前支持v8版本,未来计划支持更多版本。
github 收录
Subway Dataset
该数据集包含了全球多个城市的地铁系统数据,包括车站信息、线路图、列车时刻表、乘客流量等。数据集旨在帮助研究人员和开发者分析和模拟城市交通系统,优化地铁运营和乘客体验。
www.kaggle.com 收录