有没有相关的论文或文献参考?
这个数据集是基于什么背景创建的?
数据集的作者是谁?
能帮我联系到这个数据集的作者吗?
这个数据集如何下载?
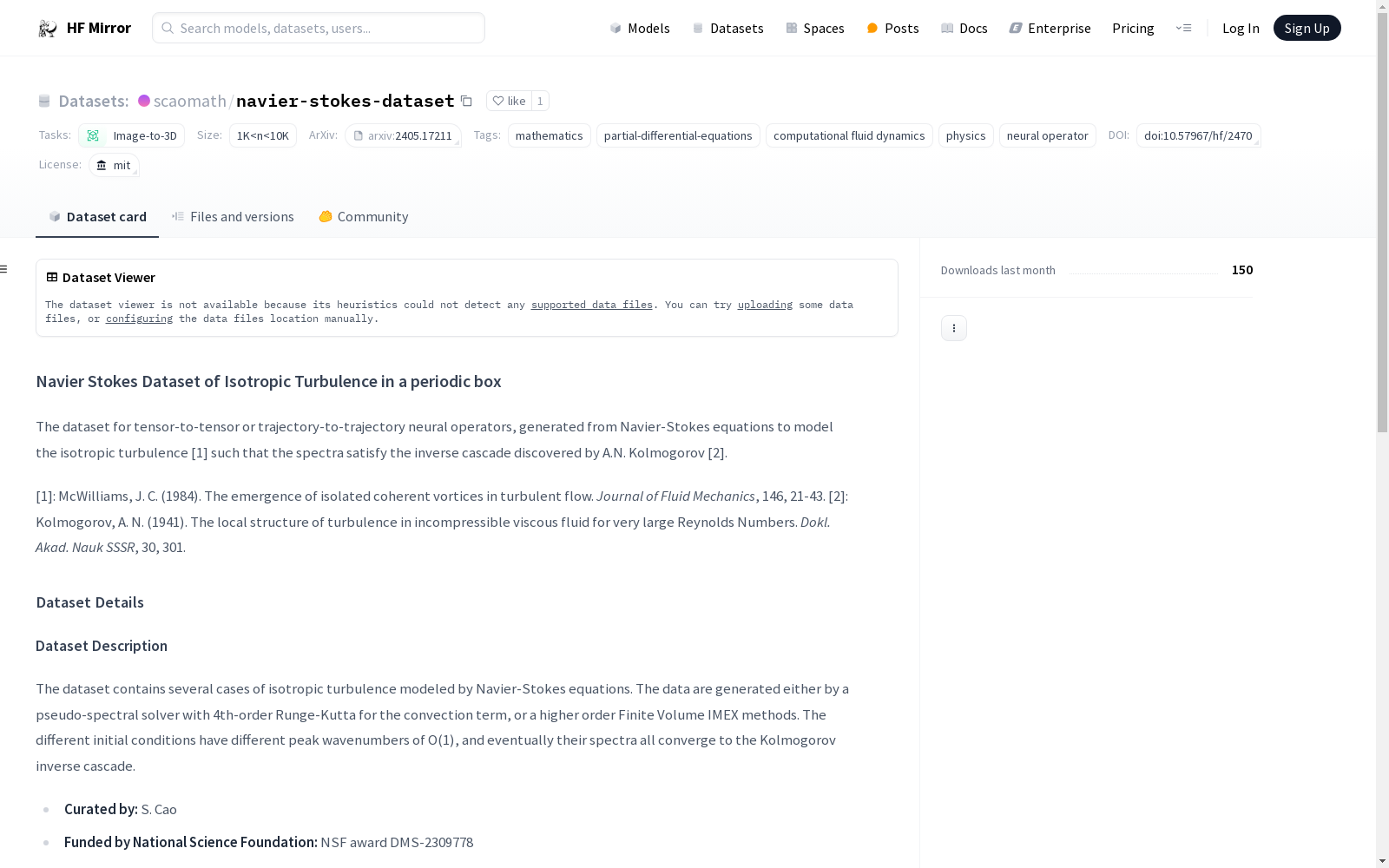
D4LA-版面分析数据集
# D4LA 文档版面分析数据集 (the most Diverse and Detailed Dataset ever for Document Layout Analysis) ## 数据集概述 D4LA是面向文档版面分析的数据集。 ### 数据集简介 包含12类文档工27类文档版面类型,详细如下:  ### 标注格式 ``` D4LA ├── train_images │ ├── 1.jpg ├── test_images │ ├── 2.jpg ├── VGT_D4LA_grid_pkl │ ├── 1.pkl │ └── 2.pkl ├── json │ ├── train.json │ └── test.json ``` ### 引用方式 If you find this repository useful, please consider citing our work: ``` @inproceedings{da2023vgt, title={Vision Grid Transformer for Document Layout Analysis}, author={Cheng Da and Chuwei Luo and Qi Zheng and Cong Yao}, year={2023}, booktitle = {ICCV}, } ``` ### Clone with HTTP ```bash git clone https://www.modelscope.cn/datasets/damo/D4LA.git ```
魔搭社区 收录
CAP-DATA
CAP-DATA数据集由长安大学交通学院的研究团队创建,包含11,727个交通事故视频,总计超过2.19百万帧。该数据集不仅标注了事故发生的时间窗口,还提供了详细的文本描述,包括事故前的实际情况、事故类别、事故原因和预防建议。数据集的创建旨在通过结合视觉和文本信息,提高交通事故预测的准确性和解释性,从而支持更安全的驾驶决策系统。
arXiv 收录
中国省级灾害统计空间分布数据集(1999-2020年)
该数据集为中国省级灾害统计空间分布数据集,时间为1999-2020年。该数据集包含中国各省自然灾害、地质灾害、地震灾害、森林火灾、森林病虫鼠害、草原灾害六类灾害的详细数据。数据量为206MB,数据格式为excel。
国家地球系统科学数据中心 收录
MedDialog
MedDialog数据集(中文)包含了医生和患者之间的对话(中文)。它有110万个对话和400万个话语。数据还在不断增长,会有更多的对话加入。原始对话来自好大夫网。
github 收录
典型分布式光伏出力预测数据集
光伏电站出力数据每5分钟从电站机房监控系统获取;气象实测数据从气象站获取,气象站建于电站30号箱变附近,每5分钟将采集的数据通过光纤传输到机房;数值天气预报数据利用中国电科院新能源气象应用机房的WRF业务系统(包括30TF计算刀片机、250TB并行存储)进行中尺度模式计算后输出预报产品,每日8点前通过反向隔离装置推送到电站内网预测系统。
国家基础学科公共科学数据中心 收录