有没有相关的论文或文献参考?
这个数据集是基于什么背景创建的?
数据集的作者是谁?
能帮我联系到这个数据集的作者吗?
这个数据集如何下载?
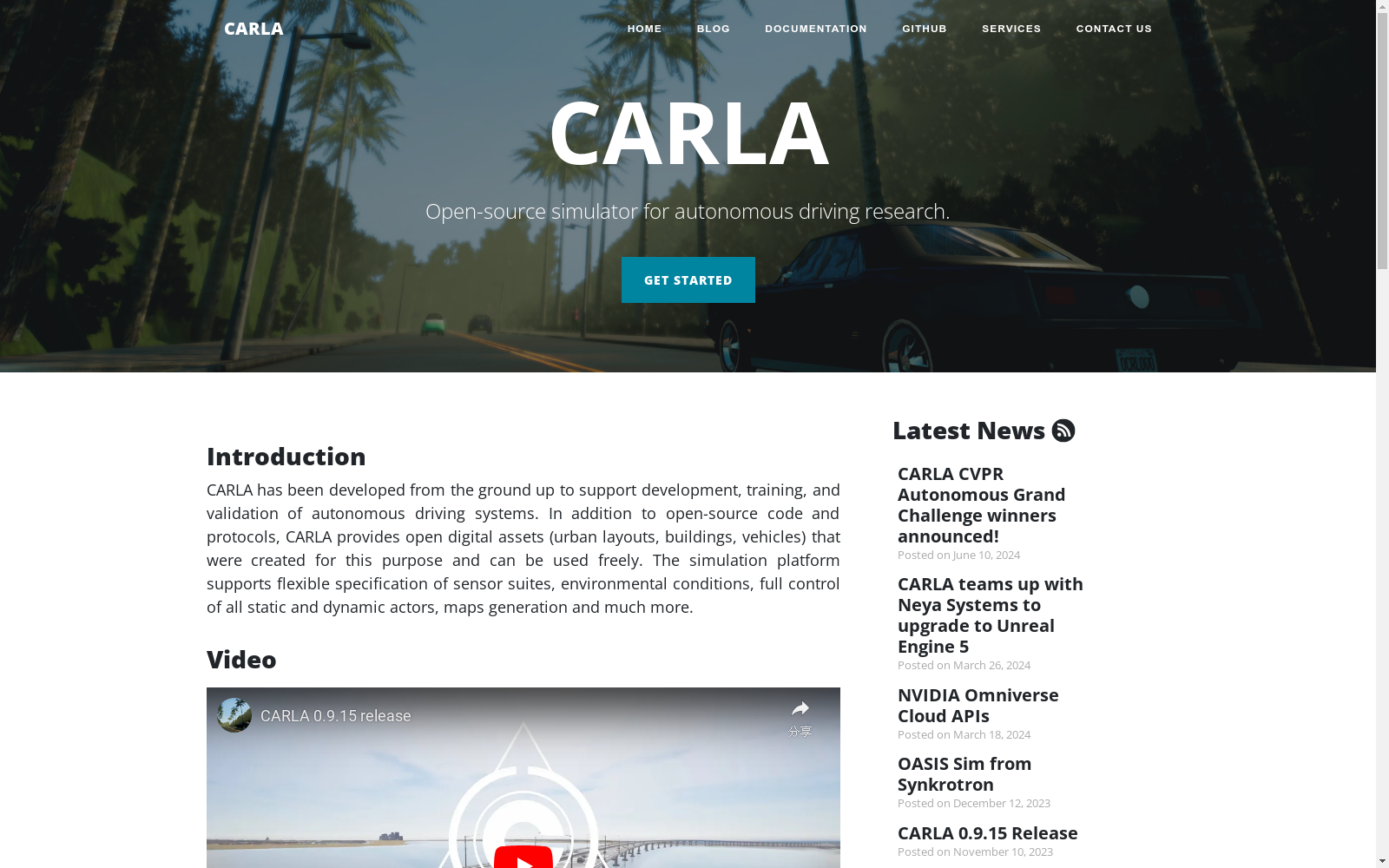
D4LA-版面分析数据集
# D4LA 文档版面分析数据集 (the most Diverse and Detailed Dataset ever for Document Layout Analysis) ## 数据集概述 D4LA是面向文档版面分析的数据集。 ### 数据集简介 包含12类文档工27类文档版面类型,详细如下:  ### 标注格式 ``` D4LA ├── train_images │ ├── 1.jpg ├── test_images │ ├── 2.jpg ├── VGT_D4LA_grid_pkl │ ├── 1.pkl │ └── 2.pkl ├── json │ ├── train.json │ └── test.json ``` ### 引用方式 If you find this repository useful, please consider citing our work: ``` @inproceedings{da2023vgt, title={Vision Grid Transformer for Document Layout Analysis}, author={Cheng Da and Chuwei Luo and Qi Zheng and Cong Yao}, year={2023}, booktitle = {ICCV}, } ``` ### Clone with HTTP ```bash git clone https://www.modelscope.cn/datasets/damo/D4LA.git ```
魔搭社区 收录
CE-CSL
CE-CSL数据集是由哈尔滨工程大学智能科学与工程学院创建的中文连续手语数据集,旨在解决现有数据集在复杂环境下的局限性。该数据集包含5,988个从日常生活场景中收集的连续手语视频片段,涵盖超过70种不同的复杂背景,确保了数据集的代表性和泛化能力。数据集的创建过程严格遵循实际应用导向,通过收集大量真实场景下的手语视频材料,覆盖了广泛的情境变化和环境复杂性。CE-CSL数据集主要应用于连续手语识别领域,旨在提高手语识别技术在复杂环境中的准确性和效率,促进聋人与听人社区之间的无障碍沟通。
arXiv 收录
Beijing Traffic
The Beijing Traffic Dataset collects traffic speeds at 5-minute granularity for 3126 roadway segments in Beijing between 2022/05/12 and 2022/07/25.
Papers with Code 收录
URPC系列数据集, S-URPC2019, UDD
URPC系列数据集包括URPC2017至URPC2020DL,主要用于水下目标的检测和分类。S-URPC2019专注于水下环境的特定检测任务。UDD数据集信息未在README中详细描述。
github 收录
ChinaTravel
ChinaTravel是由南京大学国家重点实验室开发的一个真实世界基准数据集,专门用于评估语言代理在中国旅行规划中的应用。该数据集涵盖了中国10个最受欢迎城市的旅行信息,包括720个航班和5770趟列车,以及3413个景点、4655家餐厅和4124家酒店的详细信息。数据集通过问卷调查收集用户需求,并设计了一个可扩展的领域特定语言来支持自动评估。ChinaTravel旨在解决复杂的真实世界旅行规划问题,特别是在多兴趣点行程安排和用户偏好满足方面,为语言代理在旅行规划中的应用提供了重要的测试平台。
arXiv 收录