有没有相关的论文或文献参考?
这个数据集是基于什么背景创建的?
数据集的作者是谁?
能帮我联系到这个数据集的作者吗?
这个数据集如何下载?
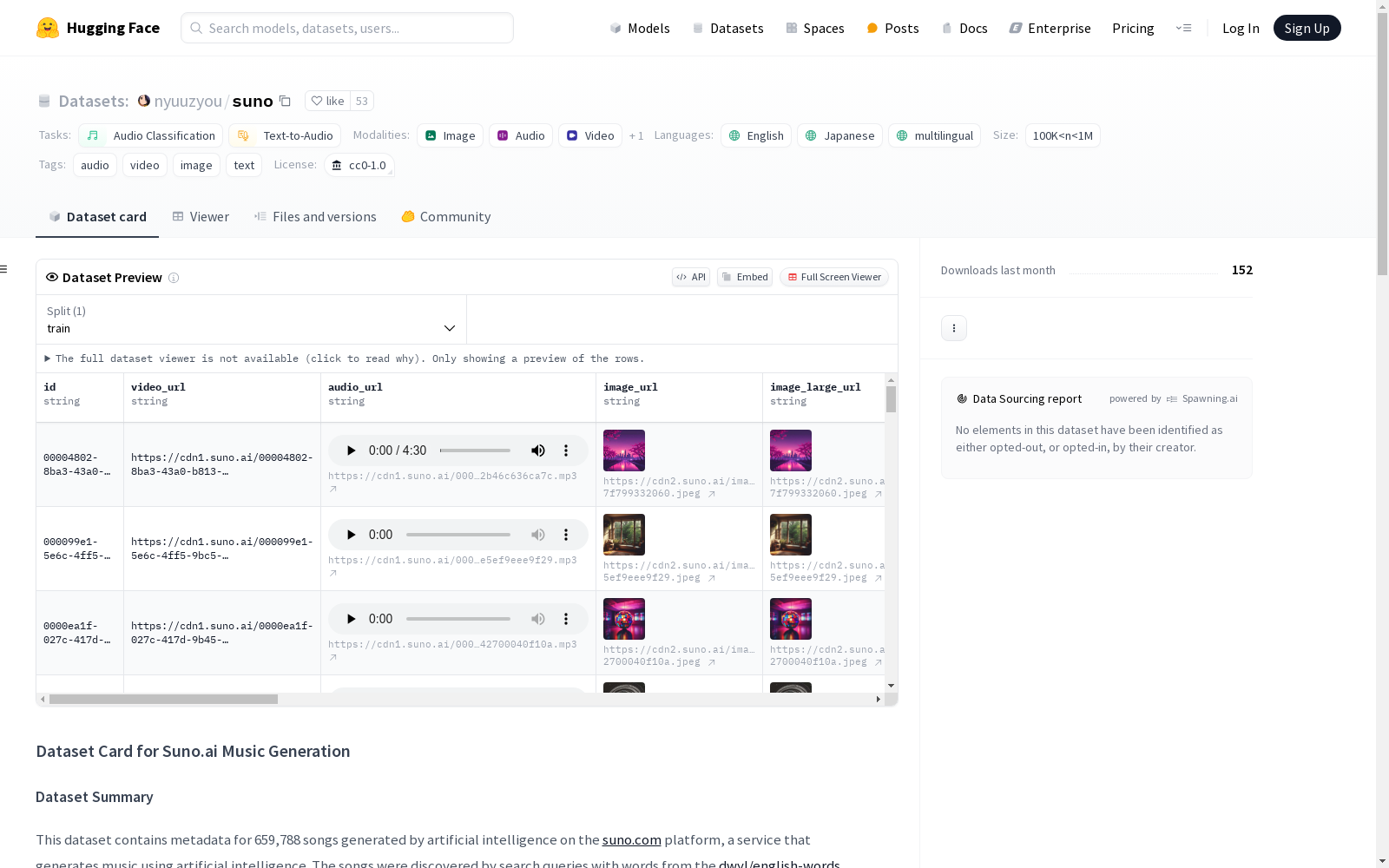
该数据集包含659,788首由人工智能生成的歌曲的元数据,这些歌曲来自suno.com平台,该平台使用人工智能生成音乐。歌曲通过dwyl/english-words词表中的词汇进行搜索查询发现。
数据集是多语言的,主要语言为英语:
每个歌曲的元数据包括:
id: 歌曲的唯一标识符 (字符串)video_url: 视频版本的URL (字符串)audio_url: 音频文件的URL (字符串)image_url: 歌曲缩略图的URL (字符串)image_large_url: 大封面图像的URL (字符串)is_video_pending: 视频处理状态 (布尔值)major_model_version: 使用的AI模型版本 (字符串)model_name: 使用的模型名称 (字符串)metadata: 额外的歌曲信息 (字典)
tags: 音乐风格和流派标签 (字符串)prompt: 用于生成歌曲的歌词/提示 (字符串)type: 生成类型 (字符串)duration: 歌曲时长(秒) (浮点数)refund_credits: 退款状态 (布尔值)stream: 流媒体可用性 (布尔值)is_liked: 喜欢状态 (布尔值)user_id: 创作者的ID (字符串)display_name: 创作者的显示名称 (字符串)handle: 创作者的句柄 (字符串)is_handle_updated: 句柄更新状态 (布尔值)avatar_image_url: 创作者的头像URL (字符串)is_trashed: 删除状态 (布尔值)created_at: 创建时间戳 (字符串)status: 生成状态 (字符串)title: 歌曲标题 (字符串)play_count: 播放次数 (整数)upvote_count: 点赞次数 (整数)is_public: 公开可见性状态 (布尔值)所有歌曲都在一个分割中。
该数据集采用Creative Commons Zero (CC0) 许可证,这意味着您可以:
Figshare
Figshare是一个在线数据共享平台,允许研究人员上传和共享各种类型的研究成果,包括数据集、论文、图像、视频等。它旨在促进科学研究的开放性和可重复性。
figshare.com 收录
中国区域交通网络数据集
该数据集包含中国各区域的交通网络信息,包括道路、铁路、航空和水路等多种交通方式的网络结构和连接关系。数据集详细记录了各交通节点的位置、交通线路的类型、长度、容量以及相关的交通流量信息。
data.stats.gov.cn 收录
MeSH
MeSH(医学主题词表)是一个用于索引和检索生物医学文献的标准化词汇表。它包含了大量的医学术语和概念,用于描述医学文献中的主题和内容。MeSH数据集包括主题词、副主题词、树状结构、历史记录等信息,广泛应用于医学文献的分类和检索。
www.nlm.nih.gov 收录
UDTIRI-Crack
UDTIRI-Crack数据集是由同济大学电子与信息工程学院等机构创建的高质量图像数据集,包含2500张来自七个公共注释数据源的图像,涵盖了不同类型的裂缝和道路表面材料,以及多种场景和照明条件。该数据集作为该领域首个全面的在线基准,用于评估现有算法在道路裂缝检测方面的性能。
arXiv 收录
中国交通事故深度调查(CIDAS)数据集
交通事故深度调查数据通过采用科学系统方法现场调查中国道路上实际发生交通事故相关的道路环境、道路交通行为、车辆损坏、人员损伤信息,以探究碰撞事故中车损和人伤机理。目前已积累深度调查事故10000余例,单个案例信息包含人、车 、路和环境多维信息组成的3000多个字段。该数据集可作为深入分析中国道路交通事故工况特征,探索事故预防和损伤防护措施的关键数据源,为制定汽车安全法规和标准、完善汽车测评试验规程、
北方大数据交易中心 收录