cogsci13/Amazon-Reviews-2023-Books-Meta
收藏资源简介:
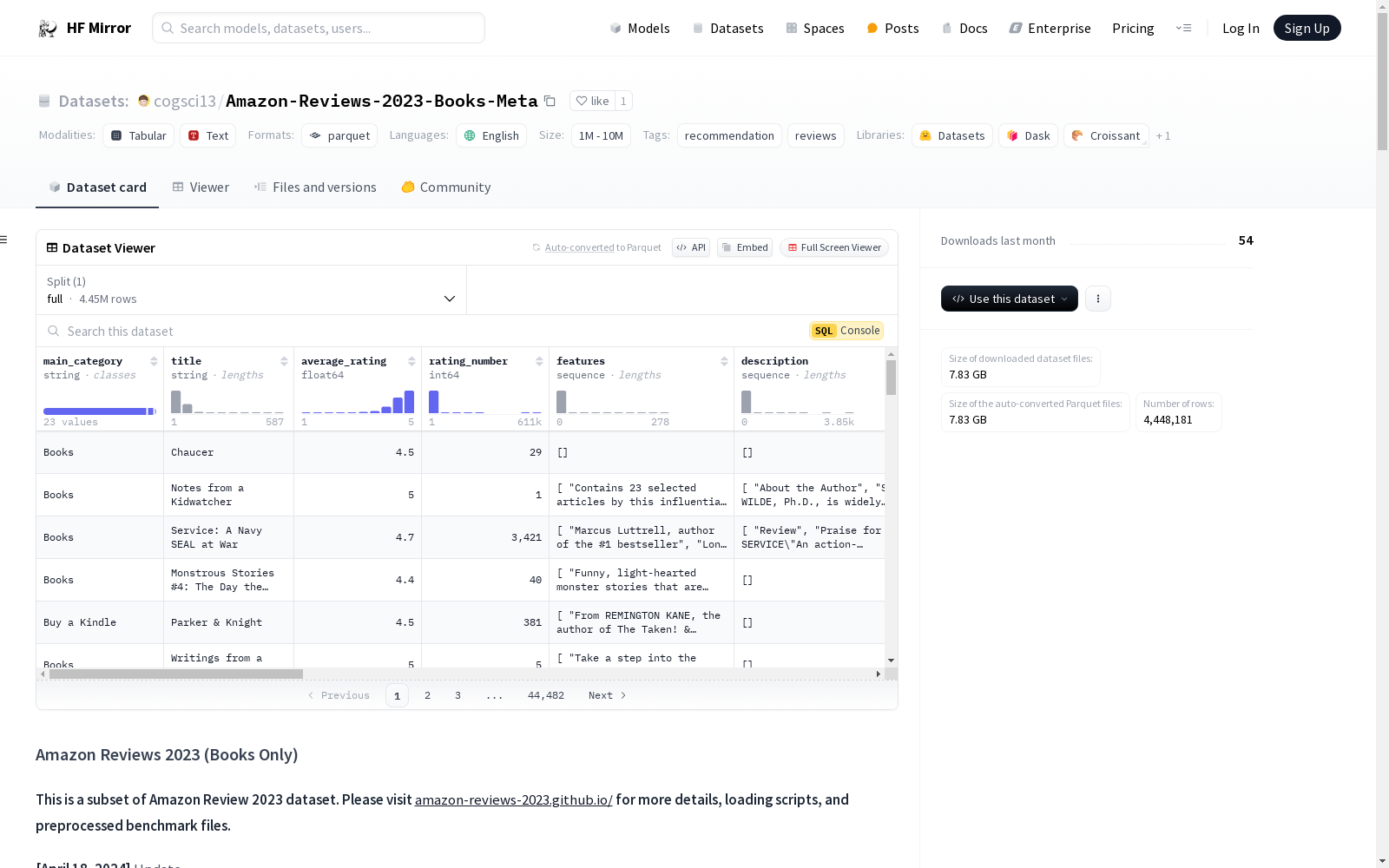
--- language: - en tags: - recommendation - reviews size_categories: - 100M<n<1B --- # Amazon Reviews 2023 (Books Only) **This is a subset of Amazon Review 2023 dataset. Please visit [amazon-reviews-2023.github.io/](https://amazon-reviews-2023.github.io/) for more details, loading scripts, and preprocessed benchmark files.** **[April 18, 2024]** Update 1. This dataset was created and pushed for the first time. --- <!-- Provide a quick summary of the dataset. --> This is a large-scale **Amazon Reviews** dataset, collected in **2023** by [McAuley Lab](https://cseweb.ucsd.edu/~jmcauley/), and it includes rich features such as: 1. **User Reviews** (*ratings*, *text*, *helpfulness votes*, etc.); 2. **Item Metadata** (*descriptions*, *price*, *raw image*, etc.); ## What's New? In the Amazon Reviews'23, we provide: 1. **Larger Dataset:** We collected 571.54M reviews, 245.2% larger than the last version; 2. **Newer Interactions:** Current interactions range from May. 1996 to Sep. 2023; 3. **Richer Metadata:** More descriptive features in item metadata; 4. **Fine-grained Timestamp:** Interaction timestamp at the second or finer level; 5. **Cleaner Processing:** Cleaner item metadata than previous versions; 6. **Standard Splitting:** Standard data splits to encourage RecSys benchmarking. ## Basic Statistics > We define the <b>#R_Tokens</b> as the number of [tokens](https://pypi.org/project/tiktoken/) in user reviews and <b>#M_Tokens</b> as the number of [tokens](https://pypi.org/project/tiktoken/) if treating the dictionaries of item attributes as strings. We emphasize them as important statistics in the era of LLMs. > We count the number of items based on user reviews rather than item metadata files. Note that some items lack metadata. ### Grouped by Category | Category | #User | #Item | #Rating | #R_Token | #M_Token | Download | | ------------------------ | ------: | ------: | --------: | -------: | -------: | ------------------------------: | | Books | 10.3M | 4.4M | 29.5M | 2.9B | 3.7B | <a href='https://datarepo.eng.ucsd.edu/mcauley_group/data/amazon_2023/raw/review_categories/Books.jsonl.gz' download> review</a>, <a href='https://datarepo.eng.ucsd.edu/mcauley_group/data/amazon_2023/raw/meta_categories/meta_Books.jsonl.gz' download> meta </a> | meta </a> | > Check Pure ID files and corresponding data splitting strategies in <b>[Common Data Processing](https://amazon-reviews-2023.github.io/data_processing/index.html)</b> section. ## Quick Start ### Load User Reviews ```python from datasets import load_dataset dataset = load_dataset("cogsci13/Amazon-Reviews-2023-Books-Review", "raw_review_Books", trust_remote_code=True) print(dataset["full"][0]) ``` ```json {'rating': {0: 1.0}, 'title': {0: 'Not a watercolor book! Seems like copies imo.'}, 'text': {0: 'It is definitely not a watercolor book. The paper bucked completely. The pages honestly appear to be photo copies of other pictures. I say that bc if you look at the seal pics you can see the tell tale line at the bottom of the page. As someone who has made many photocopies of pages in my time so I could try out different colors & mediums that black line is a dead giveaway to me. It’s on other pages too. The entire book just seems off. Nothing is sharp & clear. There is what looks like toner dust on all the pages making them look muddy. There are no sharp lines & there is no clear definition. At least there isn’t in my copy. And the Coloring Book for Adult on the bottom of the front cover annoys me. Why is it singular & not plural? They usually say coloring book for kids or coloring book for kids & adults or coloring book for adults- plural. Lol Plus it would work for kids if you can get over the grey scale nature of it. Personally I’m not going to waste expensive pens & paints trying to paint over the grey & black mess. I grew up in SW Florida minutes from the beaches & I was really excited about the sea life in this. I hope the printers & designers figure out how to clean up the mess bc some of the designs are really cute. They just aren’t worth my time to hand trace & transfer them, but I’m sure there are ppl that will be up to the challenge. This is one is a hard no. Going back. I tried.'}, 'images': {0: array([{'attachment_type': 'IMAGE', 'large_image_url': 'https://m.media-amazon.com/images/I/516HBU7LQoL._SL1600_.jpg', 'medium_image_url': 'https://m.media-amazon.com/images/I/516HBU7LQoL._SL800_.jpg', 'small_image_url': 'https://m.media-amazon.com/images/I/516HBU7LQoL._SL256_.jpg'}, {'attachment_type': 'IMAGE', 'large_image_url': 'https://m.media-amazon.com/images/I/71+XwcacMmL._SL1600_.jpg', 'medium_image_url': 'https://m.media-amazon.com/images/I/71+XwcacMmL._SL800_.jpg', 'small_image_url': 'https://m.media-amazon.com/images/I/71+XwcacMmL._SL256_.jpg'}, {'attachment_type': 'IMAGE', 'large_image_url': 'https://m.media-amazon.com/images/I/71RbTuvD1ZL._SL1600_.jpg', 'medium_image_url': 'https://m.media-amazon.com/images/I/71RbTuvD1ZL._SL800_.jpg', 'small_image_url': 'https://m.media-amazon.com/images/I/71RbTuvD1ZL._SL256_.jpg'}, {'attachment_type': 'IMAGE', 'large_image_url': 'https://m.media-amazon.com/images/I/71U63wdOeZL._SL1600_.jpg', 'medium_image_url': 'https://m.media-amazon.com/images/I/71U63wdOeZL._SL800_.jpg', 'small_image_url': 'https://m.media-amazon.com/images/I/71U63wdOeZL._SL256_.jpg'}, {'attachment_type': 'IMAGE', 'large_image_url': 'https://m.media-amazon.com/images/I/71WFEDyKcKL._SL1600_.jpg', 'medium_image_url': 'https://m.media-amazon.com/images/I/71WFEDyKcKL._SL800_.jpg', 'small_image_url': 'https://m.media-amazon.com/images/I/71WFEDyKcKL._SL256_.jpg'}, {'attachment_type': 'IMAGE', 'large_image_url': 'https://m.media-amazon.com/images/I/8109NwjpHKL._SL1600_.jpg', 'medium_image_url': 'https://m.media-amazon.com/images/I/8109NwjpHKL._SL800_.jpg', 'small_image_url': 'https://m.media-amazon.com/images/I/8109NwjpHKL._SL256_.jpg'}, {'attachment_type': 'IMAGE', 'large_image_url': 'https://m.media-amazon.com/images/I/814gxfh8wcL._SL1600_.jpg', 'medium_image_url': 'https://m.media-amazon.com/images/I/814gxfh8wcL._SL800_.jpg', 'small_image_url': 'https://m.media-amazon.com/images/I/814gxfh8wcL._SL256_.jpg'}, {'attachment_type': 'IMAGE', 'large_image_url': 'https://m.media-amazon.com/images/I/81HC0vKRC2L._SL1600_.jpg', 'medium_image_url': 'https://m.media-amazon.com/images/I/81HC0vKRC2L._SL800_.jpg', 'small_image_url': 'https://m.media-amazon.com/images/I/81HC0vKRC2L._SL256_.jpg'}, {'attachment_type': 'IMAGE', 'large_image_url': 'https://m.media-amazon.com/images/I/81Nx6BnRLxL._SL1600_.jpg', 'medium_image_url': 'https://m.media-amazon.com/images/I/81Nx6BnRLxL._SL800_.jpg', 'small_image_url': 'https://m.media-amazon.com/images/I/81Nx6BnRLxL._SL256_.jpg'}, {'attachment_type': 'IMAGE', 'large_image_url': 'https://m.media-amazon.com/images/I/81QQMwBcVPL._SL1600_.jpg', 'medium_image_url': 'https://m.media-amazon.com/images/I/81QQMwBcVPL._SL800_.jpg', 'small_image_url': 'https://m.media-amazon.com/images/I/81QQMwBcVPL._SL256_.jpg'}, {'attachment_type': 'IMAGE', 'large_image_url': 'https://m.media-amazon.com/images/I/81fgT3R3OwL._SL1600_.jpg', 'medium_image_url': 'https://m.media-amazon.com/images/I/81fgT3R3OwL._SL800_.jpg', 'small_image_url': 'https://m.media-amazon.com/images/I/81fgT3R3OwL._SL256_.jpg'}, {'attachment_type': 'IMAGE', 'large_image_url': 'https://m.media-amazon.com/images/I/81mfzny0I5L._SL1600_.jpg', 'medium_image_url': 'https://m.media-amazon.com/images/I/81mfzny0I5L._SL800_.jpg', 'small_image_url': 'https://m.media-amazon.com/images/I/81mfzny0I5L._SL256_.jpg'}, {'attachment_type': 'IMAGE', 'large_image_url': 'https://m.media-amazon.com/images/I/81nir7bf91L._SL1600_.jpg', 'medium_image_url': 'https://m.media-amazon.com/images/I/81nir7bf91L._SL800_.jpg', 'small_image_url': 'https://m.media-amazon.com/images/I/81nir7bf91L._SL256_.jpg'}, {'attachment_type': 'IMAGE', 'large_image_url': 'https://m.media-amazon.com/images/I/81yLUo6ZL3L._SL1600_.jpg', 'medium_image_url': 'https://m.media-amazon.com/images/I/81yLUo6ZL3L._SL800_.jpg', 'small_image_url': 'https://m.media-amazon.com/images/I/81yLUo6ZL3L._SL256_.jpg'}, {'attachment_type': 'IMAGE', 'large_image_url': 'https://m.media-amazon.com/images/I/81zh9h5RwkL._SL1600_.jpg', 'medium_image_url': 'https://m.media-amazon.com/images/I/81zh9h5RwkL._SL800_.jpg', 'small_image_url': 'https://m.media-amazon.com/images/I/81zh9h5RwkL._SL256_.jpg'}, {'attachment_type': 'IMAGE', 'large_image_url': 'https://m.media-amazon.com/images/I/91yfcpFlEqL._SL1600_.jpg', 'medium_image_url': 'https://m.media-amazon.com/images/I/91yfcpFlEqL._SL800_.jpg', 'small_image_url': 'https://m.media-amazon.com/images/I/91yfcpFlEqL._SL256_.jpg'}], dtype=object)}, 'asin': {0: 'B09BGPFTDB'}, 'parent_asin': {0: 'B09BGPFTDB'}, 'user_id': {0: 'AFKZENTNBQ7A7V7UXW5JJI6UGRYQ'}, 'timestamp': {0: 1642399598485}, 'helpful_vote': {0: 0}, 'verified_purchase': {0: True}} ``` ### Load Item Metadata ```python dataset = load_dataset("cogsci13/Amazon-Reviews-2023-Books-Meta", "raw_meta_Books", split="full", trust_remote_code=True) print(dataset[0]) ``` ```json {'main_category': {0: 'Books'}, 'title': {0: 'Chaucer'}, 'average_rating': {0: 4.5}, 'rating_number': {0: 29}, 'features': {0: array([], dtype=object)}, 'description': {0: array([], dtype=object)}, 'price': {0: '8.23'}, 'images': {0: {'hi_res': array([None], dtype=object), 'large': array(['https://m.media-amazon.com/images/I/41X61VPJYKL._SX334_BO1,204,203,200_.jpg'], dtype=object), 'thumb': array([None], dtype=object), 'variant': array(['MAIN'], dtype=object)}}, 'videos': {0: {'title': array([], dtype=object), 'url': array([], dtype=object), 'user_id': array([], dtype=object)}}, 'store': {0: 'Peter Ackroyd (Author)'}, 'categories': {0: array(['Books', 'Literature & Fiction', 'History & Criticism'], dtype=object)}, 'details': {0: '{"Publisher": "Chatto & Windus; First Edition (January 1, 2004)", "Language": "English", "Hardcover": "196 pages", "ISBN 10": "0701169850", "ISBN 13": "978-0701169855", "Item Weight": "10.1 ounces", "Dimensions": "5.39 x 0.71 x 7.48 inches"}'}, 'parent_asin': {0: '0701169850'}, 'bought_together': {0: None}, 'subtitle': {0: 'Hardcover – Import, January 1, 2004'}, 'author': {0: "{'avatar': 'https://m.media-amazon.com/images/I/21Je2zja9pL._SY600_.jpg', 'name': 'Peter Ackroyd', 'about': ['Peter Ackroyd, (born 5 October 1949) is an English biographer, novelist and critic with a particular interest in the history and culture of London. For his novels about English history and culture and his biographies of, among others, William Blake, Charles Dickens, T. S. Eliot and Sir Thomas More, he won the Somerset Maugham Award and two Whitbread Awards. He is noted for the volume of work he has produced, the range of styles therein, his skill at assuming different voices and the depth of his research.', 'He was elected a fellow of the Royal Society of Literature in 1984 and appointed a Commander of the Order of the British Empire in 2003.', 'Bio from Wikipedia, the free encyclopedia.']}"}} ``` > Check data loading examples and Huggingface datasets APIs in <b>[Common Data Loading](https://amazon-reviews-2023.github.io/data_loading/index.html)</b> section. ## Data Fields ### For User Reviews | Field | Type | Explanation | | ----- | ---- | ----------- | | rating | float | Rating of the product (from 1.0 to 5.0). | | title | str | Title of the user review. | | text | str | Text body of the user review. | | images | list | Images that users post after they have received the product. Each image has different sizes (small, medium, large), represented by the small_image_url, medium_image_url, and large_image_url respectively. | | asin | str | ID of the product. | | parent_asin | str | Parent ID of the product. Note: Products with different colors, styles, sizes usually belong to the same parent ID. The “asin” in previous Amazon datasets is actually parent ID. <b>Please use parent ID to find product meta.</b> | | user_id | str | ID of the reviewer | | timestamp | int | Time of the review (unix time) | | verified_purchase | bool | User purchase verification | | helpful_vote | int | Helpful votes of the review | ### For Item Metadata | Field | Type | Explanation | | ----- | ---- | ----------- | | main_category | str | Main category (i.e., domain) of the product. | | title | str | Name of the product. | | average_rating | float | Rating of the product shown on the product page. | | rating_number | int | Number of ratings in the product. | | features | list | Bullet-point format features of the product. | | description | list | Description of the product. | | price | float | Price in US dollars (at time of crawling). | | images | list | Images of the product. Each image has different sizes (thumb, large, hi_res). The “variant” field shows the position of image. | | videos | list | Videos of the product including title and url. | | store | str | Store name of the product. | | categories | list | Hierarchical categories of the product. | | details | dict | Product details, including materials, brand, sizes, etc. | | parent_asin | str | Parent ID of the product. | | bought_together | list | Recommended bundles from the websites. | ## Citation ```bibtex @article{hou2024bridging, title={Bridging Language and Items for Retrieval and Recommendation}, author={Hou, Yupeng and Li, Jiacheng and He, Zhankui and Yan, An and Chen, Xiusi and McAuley, Julian}, journal={arXiv preprint arXiv:2403.03952}, year={2024} } ``` ## Contact Us - **Report Bugs**: To report bugs in the dataset, please file an issue on our [GitHub](https://github.com/hyp1231/AmazonReviews2023/issues/new). - **Others**: For research collaborations or other questions, please email **yphou AT ucsd.edu**.
数据集概述:Amazon Reviews 2023 (Books Only)
数据集基本信息
- 名称: Amazon Reviews 2023 (Books Only)
- 语言: 英语
- 标签: 推荐系统, 评论
- 大小: 100M<n<1B
数据集内容
- 来源: 由McAuley Lab在2023年收集
- 包含内容:
- 用户评论: 包括评分、文本、有用投票等;
- 商品元数据: 包括描述、价格、原始图像等。
数据集更新
- 首次发布: 2024年4月18日
- 更新内容:
- 数据集大小: 收集了571.54M条评论,比上一版本大245.2%;
- 交互时间范围: 从1996年5月到2023年9月;
- 元数据丰富度: 增加了商品元数据的描述性特征;
- 时间戳精度: 交互时间戳精度达到秒级或更细;
- 数据处理: 商品元数据比之前版本更清洁;
- 标准分割: 提供标准的数据分割,以促进推荐系统基准测试。
数据集统计
- 分类统计:
数据集字段
用户评论
| 字段 | 类型 | 说明 |
|---|---|---|
| rating | float | 产品评分(1.0到5.0) |
| title | str | 用户评论标题 |
| text | str | 用户评论文本 |
| images | list | 用户上传的产品图像 |
| asin | str | 产品ID |
| parent_asin | str | 产品父ID |
| user_id | str | 评论者ID |
| timestamp | int | 评论时间(Unix时间) |
| verified_purchase | bool | 用户购买验证 |
| helpful_vote | int | 评论的有用投票 |
商品元数据
| 字段 | 类型 | 说明 |
|---|---|---|
| main_category | str | 产品主类别 |
| title | str | 产品名称 |
| average_rating | float | 产品页面显示的评分 |
| rating_number | int | 产品评分数量 |
| features | list | 产品特征(点格式) |
| description | list | 产品描述 |
| price | float | 产品价格(爬取时) |
| images | list | 产品图像 |
| videos | list | 产品视频 |
| store | str | 产品商店名称 |
| categories | list | 产品类别层次 |
| details | dict | 产品详细信息 |
| parent_asin | str | 产品父ID |
| bought_together | list | 网站推荐的捆绑销售 |
数据集引用
bibtex @article{hou2024bridging, title={Bridging Language and Items for Retrieval and Recommendation}, author={Hou, Yupeng and Li, Jiacheng and He, Zhankui and Yan, An and Chen, Xiusi and McAuley, Julian}, journal={arXiv preprint arXiv:2403.03952}, year={2024} }