有没有相关的论文或文献参考?
这个数据集是基于什么背景创建的?
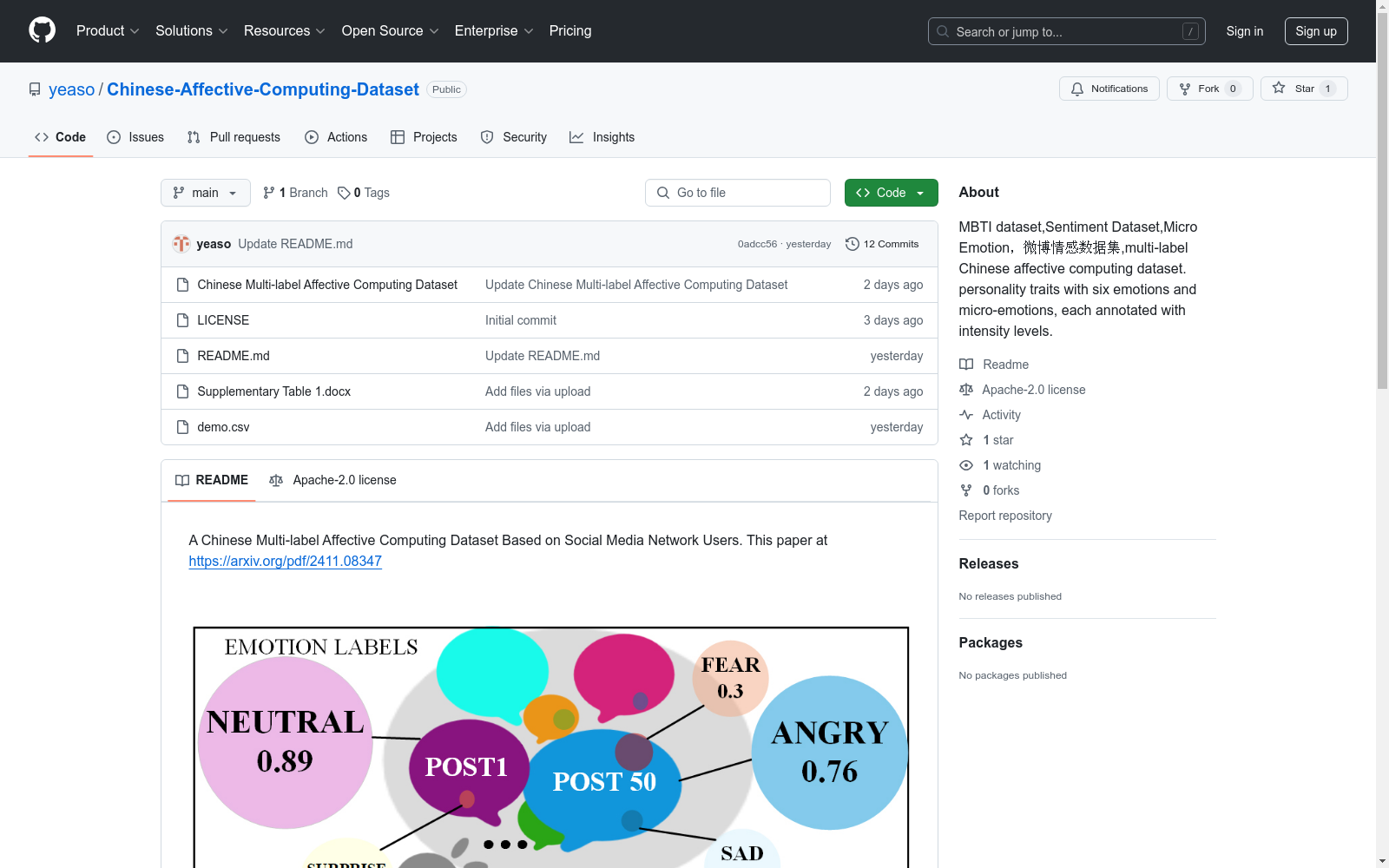
数据集的作者是谁?
能帮我联系到这个数据集的作者吗?
这个数据集如何下载?
Beijing Traffic
The Beijing Traffic Dataset collects traffic speeds at 5-minute granularity for 3126 roadway segments in Beijing between 2022/05/12 and 2022/07/25.
Papers with Code 收录
Subway Dataset
该数据集包含了全球多个城市的地铁系统数据,包括车站信息、线路图、列车时刻表、乘客流量等。数据集旨在帮助研究人员和开发者分析和模拟城市交通系统,优化地铁运营和乘客体验。
www.kaggle.com 收录
中国知识产权局专利数据库
该数据集包含了中国知识产权局发布的专利信息,涵盖了专利的申请、授权、转让等详细记录。数据内容包括专利号、申请人、发明人、申请日期、授权日期、专利摘要等。
www.cnipa.gov.cn 收录
中国陆域及周边逐日1km全天候地表温度数据集(TRIMS LST;2000-2023)
地表温度(Land surface temperature, LST)是地球表面与大气之间界面的重要参量之一。它既是地表与大气能量交互作用的直接体现,又对于地气过程具有复杂的反馈作用。因此,地表温度不仅是气候变化的敏感指示因子和掌握气候变化规律的重要前提,还是众多模型的直接输入参数,在许多领域有广泛的应用,如气象气候、环境生态、水文等。伴随地学及相关领域研究的深入和精细化,学术界对卫星遥感的全天候地表温度(All-weather LST)具有迫切的需求。 本数据集的制备方法是增强型的卫星热红外遥感-再分析数据集成方法。方法的主要输入数据为Terra/Aqua MODIS LST产品和GLDAS等数据,辅助数据包括卫星遥感提供的植被指数、地表反照率等。方法充分利用了卫星热红外遥感和再分析数据提供的地表温度高频分量、低频分量以及地表温度的空间相关性,最终重建得到较高质量的全天候地表温度数据集。 评价结果表明,本数据集具有良好的图像质量和精度,不仅在空间上无缝,还与当前学术界广泛采用的逐日1 km Terra/Aqua MODIS LST产品在幅值和空间分布上具有较高的一致性。当以MODIS LST为参考时,该数据集在白天和夜间的平均偏差(MBE)为0.09K和-0.03K,偏差标准差(STD)为1.45K和1.17K。基于19个站点实测数据的检验结果表明,其MBE为-2.26K至1.73K,RMSE为0.80K至3.68K,且在晴空与非晴空条件下无显著区别。 本数据集的时间分辨率为逐日4次,空间分辨率为1km,时间跨度为2000年-2023年;空间范围包括我国陆域的主要区域(包含港澳台地区,暂不包含我国南海诸岛)及周边区域(72°E-135°E,19°N-55°N)。本数据集的缩写名为TRIMS LST(Thermal and Reanalysis Integrating Moderate-resolution Spatial-seamless LST),以便用户使用。需要说明的是,TRIMS LST的空间子集TRIMS LST-TP(中国西部逐日1 km全天候地表温度数据集(TRIMS LST-TP;2000-2023)V2)同步在国家青藏高原科学数据中心发布,以减少相关用户数据下载和处理的工作量。
国家青藏高原科学数据中心 收录
中国区域教育数据库
该数据集包含了中国各区域的教育统计数据,涵盖了学校数量、学生人数、教师资源、教育经费等多个方面的信息。
www.moe.gov.cn 收录